THE ZOO
The Hook
When I wrote this, I kept thinking about Upton Sinclair walking into the meatpacking plants for The Jungle. He didn’t go in looking for metaphor — he went in to see how the machinery actually worked. What he found wasn’t just production at scale; it was waste, opacity, and a system optimized for throughput over clarity. The surface looked efficient. The inside told a different story.
Modern AI — especially consumer-grade AI — feels similar. From the outside, it’s sleek interfaces, instant outputs, magical demos. Underneath, it’s layers of duplicated compute, isolated inference passes, memory churn, black-box graphs running side by side without coordination. We’ve industrialized pattern generation, but we rarely audit the factory floor. The point isn’t outrage — it’s awareness. If we’re going to build the next layer of infrastructure on top of these systems, we should understand how the assembly line actually runs.
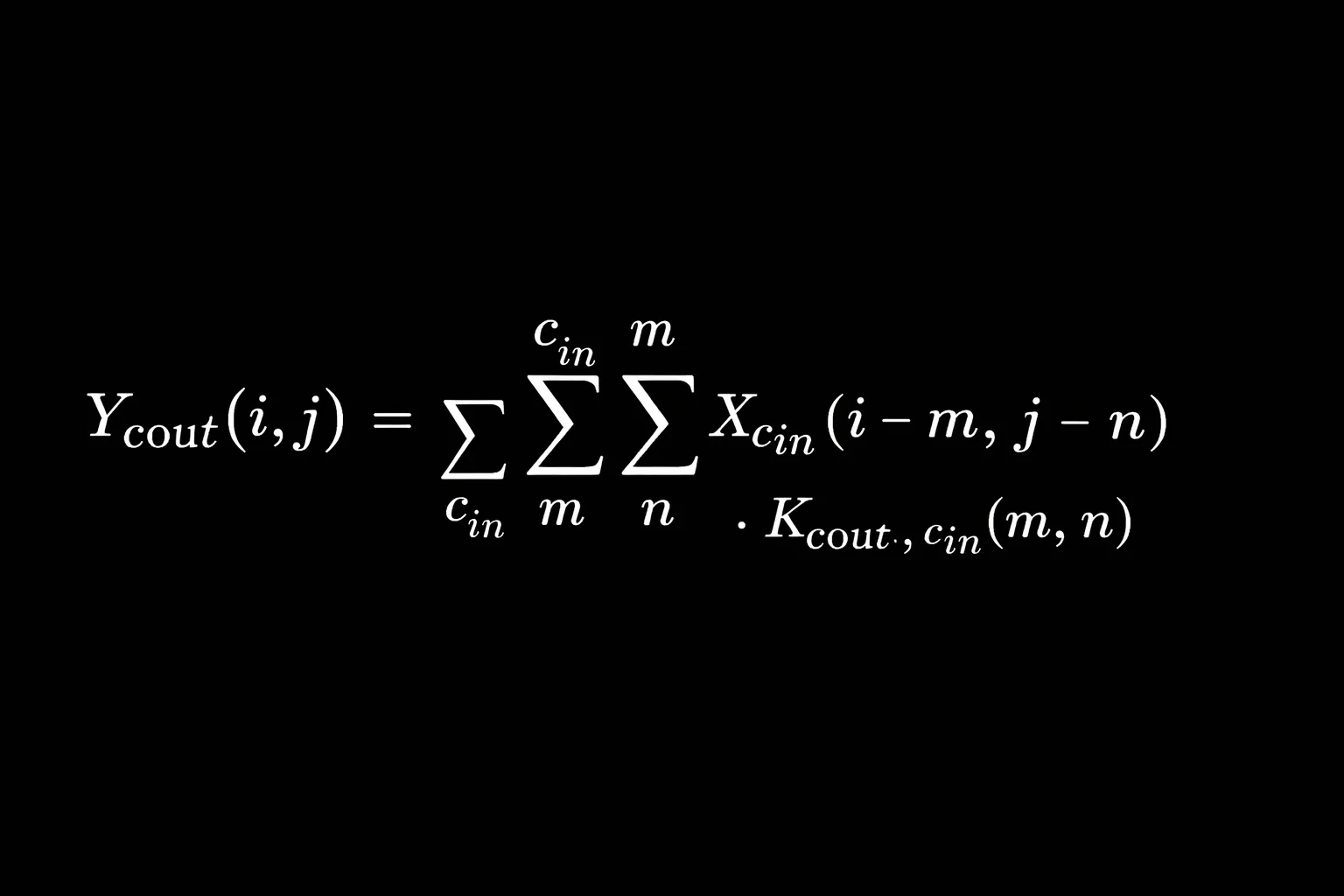
Enter the Zoo
Over the past few months, as I’ve taken apart more modern AI systems — reading the papers, tracing the graphs, inspecting the ONNX exports — something hasn’t been sitting right with me. Not hype. Not headlines. The actual mechanics. The way these systems are wired and shipped. And the more I look at them, the more I’m surprised that more engineers aren’t pushing on the same questions.
When I talk about “THE ZOO,” I’m talking about the model zoo most of us quietly live inside. A collection of pretrained networks — detectors, encoders, segmenters, diffusers — each living in its own cage, each wrapped in its own API, each doing its job without ever acknowledging the others. I’ve been digging through these animals lately — pulling apart ONNX graphs, inspecting layers, tracing tensor flows — and what stands out isn’t how different they are, but how similar they are under the hood. Convolutions. Attention blocks. Normalization layers. Feature pyramids. The same bones showing up in different skins.
The Zoo, as it exists today, is convenient — but it’s also compartmentalized. We feed one animal, take its output, walk it over to the next cage, and repeat. Over and over. What if instead of stacking cages, we understood the shared anatomy? What if the Zoo wasn’t a collection of sealed exhibits, but a mapped ecosystem where graphs could interoperate and tensors could move freely between species? That’s the question that keeps pulling me deeper.
The Cost of Black Boxes
The black-box mentality in model development comes with real architectural costs.
Most AI workflows today are multi-pass pipelines. Face detection, embeddings, segmentation, diffusion, refinement — and under the hood, many of these systems rely on the same foundational building blocks: convolution layers, attention blocks, feature pyramids, normalization passes, similar tensor transforms.
Yet because models are shipped as opaque endpoints, we repeatedly execute overlapping compute without visibility into the underlying graph.
From a systems engineering perspective, that’s inefficient.
We recompute identical intermediate representations.
We duplicate GPU memory transfers.
We rerun embedding encoders (CLIP, ArcFace, etc.) across separate tools.
We stack isolated inference calls instead of composing unified build graphs where tensors could be shared and reused.
The result is unnecessary compute burn — especially in multi-stage AI pipelines.
Protecting IP makes sense. But when internal graphs are sealed off, we lose the ability to collapse shared subgraphs, schedule compute intelligently, or fuse operations across workflows. And that raises a harder question: where does the IP actually live? Is it the algorithm — the arrangement of layers, the training tricks, the optimizer schedules — or is it the content the model was trained on? The math behind most of these systems isn’t new. Convolutions, attention, normalization — they’ve been published for years. What’s proprietary is often the data and the fine-tuning strategy. When we seal off the entire graph in the name of protection, we aren’t just protecting training content — we’re blocking architectural efficiency. There’s a difference between guarding what was learned and hiding how the machine is wired.
It isn’t the algorithm that carries value — it’s the content. The memories. The lived experience. The human work that gives the output weight. The math is structure. The model is machinery. What gives it meaning is the data it absorbed — the art, the writing, the conversations, the history. And now we’re mass-producing derivative output at scale, often detached from the people who shaped the originals. The system optimizes patterns, but it doesn’t feel the source. That disconnect is worth talking about — not to stop progress, but to understand what we’re industrializing.
Instead of stacking black boxes, we should be thinking in terms of graph-level orchestration and modular tensor pipelines.
Efficiency in AI won’t just come from bigger models.
It will come from better systems design.

The Fundamental Pattern Being Recomputed - The Receipt
At the heart of most modern vision models lies the 2D convolution operation.
For an input tensor X and kernel K, the convolution at position (i, j) is:
\[
Y(i, j) = \sum_m \sum_n X(i - m, j - n) \cdot K(m, n)
\]
In practice, this expands across channels:
\[
Y_{c_{out}}(i, j) =
\sum_{c_{in}}
\sum_m
\sum_n
X_{c_{in}}(i - m, j - n)
\cdot
K_{c_{out}, c_{in}}(m, n)
\]
This same primitive:
- Extracts edges
- Builds hierarchical features
- Feeds attention blocks
- Powers U-Net backbones
- Drives detection heads
- Generates embeddings
And yet, in multi-model pipelines, we often recompute nearly identical feature maps multiple times across isolated inference calls.
And convolution isn’t the only animal pacing in circles. Attention blocks repeatedly compute scaled dot-products over nearly identical embeddings. Normalization layers rescale the same feature distributions across separate passes. Encoders regenerate embeddings that were already computed moments earlier in another cage. GPU memory is allocated, copied, freed, and reallocated for tensors that could have been shared. The Zoo isn’t inefficient because the animals are weak — it’s inefficient because they’re isolated. When shared feature maps, cached embeddings, and unified execution graphs replace stacked inference calls, the cages disappear and the ecosystem starts behaving like a system instead of a collection.
It’s Just Math
At a mathematical level, most of this isn’t mystical at all — it’s linear algebra, probability, matrix multiplications, and optimization. Weighted sums. Dot products. Gradient descent. That’s the machinery. But the jargon cloud around it — “foundation models,” “emergent reasoning,” “agentic cognition” — makes it feel like something untouchable. The real distraction isn’t the math; it’s the mythology. When we treat models as sacred black boxes instead of graphs of tensors and transforms, we’re not protecting complexity — we’re avoiding it. That black-box mentality isn’t depth. It’s a camel with its head in the sand, pretending the system is unknowable so we don’t have to look at how it actually works.
Back to Fundamentals
The information age isn’t dying because we have too much knowledge — it’s faltering because we’ve stopped grounding that knowledge in fundamentals. We stack abstractions on abstractions, wrap systems in layers of convenience, and forget the math, the graphs, the mechanics underneath. Before we let the python out of the Zoo and watch it coil around systems we barely understand, we need to return to primitives — tensors, transforms, data flow, architecture. Not to go backward, but to build forward with clarity. Tools don’t strangle civilizations; ignorance of their foundations does.
Maybe the zoo was never about animals at all. Maybe it’s just a mirror with better lighting. We build cages, label behaviors, study patterns — and then act surprised when we recognize ourselves pacing inside them. The difference between humans and the animals in the exhibit isn’t instinct; it’s the story we tell about it.
We’re beyond the gatekeeping of yesterday. The knowledge that once lived behind university walls or corporate doors now sits in public repositories, open papers, shared weights, and transparent discussions. We have centuries of mathematics, engineering, philosophy, and science at our fingertips — searchable, remixable, testable. The gaps are shrinking fast. Patterns that used to take decades to uncover now surface in months. And sooner or later, something will emerge — a discovery, a synthesis, a reframing — that forces us to rethink not just our tools, but ourselves.
That’s the part that excites me. New concepts. New patterns. New designs. The universe isn’t static — it’s layered, recursive, beautiful. We’re not at the end of understanding; we’re at the edge of it. And if we choose curiosity over mystique, systems over cages, clarity over gatekeeping — then the Zoo becomes something else entirely. Not a collection of isolated exhibits, but a living ecosystem we actually understand.

This is just the tip of the iceberg. I could go for hours about other inefficiencies — this piece mainly scratches the surface around image generation pipelines and the way we’re stacking compute without thinking systemically. Next, I want to dig into large language models and what’s happening there — because the same patterns are showing up again. The farm next door isn’t staying a farm for long; it’s turning into a data center.
Same Bat time Same Bat channel. JK
John Janes aka drezdin (your friendly neighborhood hacker)